Introduction to Recommendation Problem#
The main idea of recommendation is to rank relevant items according to some criterion. As it was mentioned earlier, recommender systems intersect with a ranking problem: smart news feed, contacts recommendation, search response ranking, suggesting point B in ride – all this stuff can be referred to as personal ranking.
Recommender systems are a type of machine learning model that use data about an individual’s preferences and interests to make personalized product or service recommendations. These systems are often used by online streaming platforms such as OKKO, and retailers to suggest films/items that watchers/customers may be interested in. They are also used in other industries such as streaming music services, online dating sites, and social networks.
Recommenders analyze data about users and their behavior, such as what they have watched or rated, and how much time they have spent interacting with an item. The data is then used to make predictions about what items a user may be interested in. For example, an online streaming service may use the data to recommend a film or song that the user is likely to interact with them based on their past preferences.
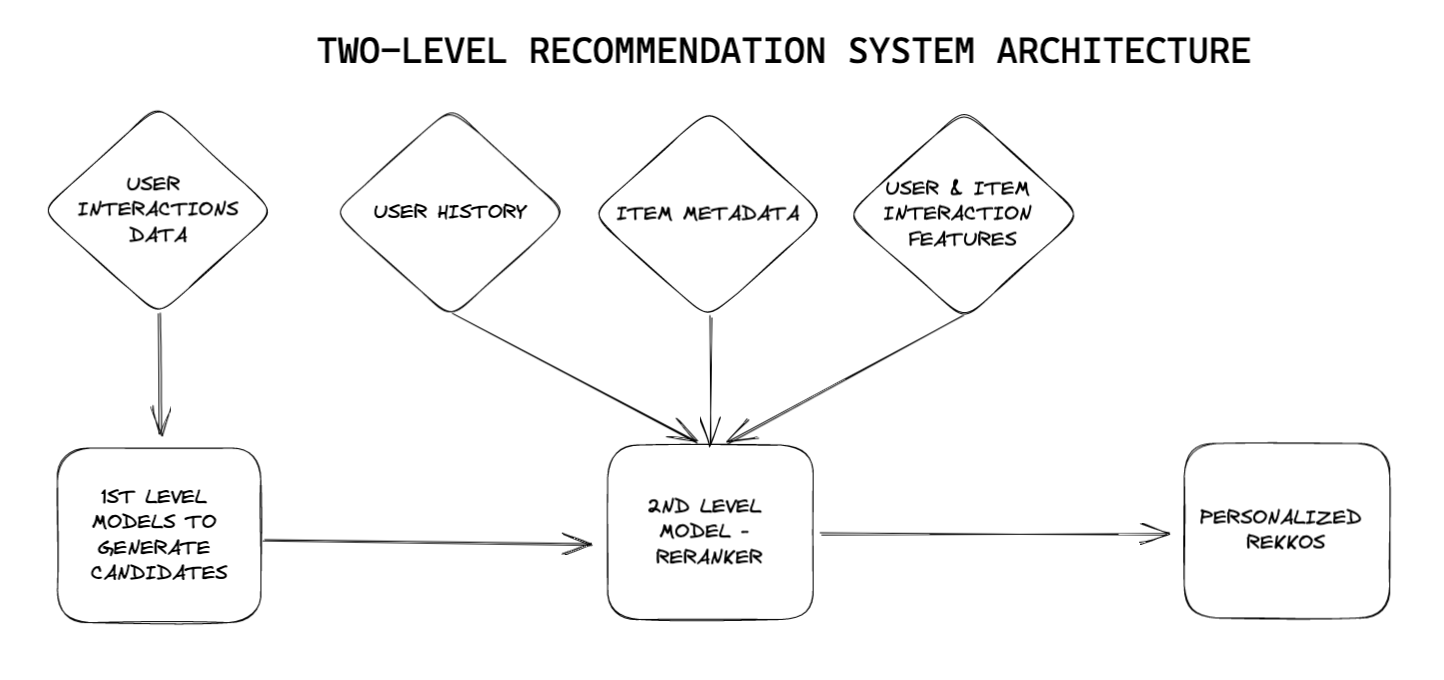
Mostly, two-level architecture is used – it makes use of two separate components each with its distinct purpose. It can be viewed as candidate generation and personalization levels. Together they provide an effective and efficient way to recommend relevant items to users. At the candidate generation level, the system processes explicit and implicit user data to generate recommendations. These recommendations are based on observed user behavior, including ratings and watched history, combined with the characteristics of the available items and the relationships between them. The system may also leverage additional external data sources, such as social media, to gather more precise and detailed insights.
At the user personalization level, the system further refines the recommendations generated from the 1st level. This further refinement is done using machine learning algorithms. These algorithms are used to create a personalized user profile that reflects an individual’s preferences and interests. This profile is then used to tailor the recommendations to each user, ensuring that the items suggested are truly relevant to them.
Overall, we generate candidates that we consider relevant for a user/search query. This means we try to maximize recall first (all possible candidates that might be clicked i.e. all 1 must be found). Then, we try to rank such that the most relevant ones are on top – in this scenario, we maximize precision – how many relevant items we put on top. Thus, the difference often occurs in the first-level models. In the ranking part it is quite similar. Now, let’s focus on recommendations.
The first-level model can be divided into two main types: content-based and collaborative filtering. However, the hybrid scheme when we mix both types is used as well. Content-based systems use information about an item’s features and compare them to the features of items a customer has previously interacted with. For example, in OKKO our service may use information about a film’s genre, actors, and other meta-information to determine how similar it is to films the user has previously watched.

Collaborative filtering systems use data from other users to make predictions. This type of system looks for patterns in the data from a group of users and uses them to make recommendations for individual users. For instance, if a group of users all watched the same film, a collaborative filtering system may recommend that film to other users who have similar watched titles.

Furthermore, recommender systems have been successfully used in a variety of industries. Amazon is a popular example of a company that has used these systems to recommend items to customers. Other companies that use these systems include Netflix for movie recommendations, Spotify for music recommendations, and Tinder for dating recommendations.
Overall, recommender systems have become increasingly popular in recent years due to the rise of online cinemas like OKKO, Netflix, etc., and the availability of large amounts of data. Many companies use these systems to personalize their products and services, which can lead to increased customer satisfaction and loyalty. They can also help companies reduce costs by recommending items that are more likely to be interacted with by users.
Regarding data, in recommendations, we need user-item interaction and metadata of both. Usually, two-level architecture is used in industry to develop robust recommendations. First, we generate candidates based on some embeddings from content-based / collaborative filtering or other techniques aiming for the highest recall i.e. get as much relevant candidates for each user. Then, we try to maximize the likelihood of interactions by ranking the most relevant ones from the first-level model to get the highest precision. Therefore,
In the first level model, we use embeddings and some similarity metrics to generate candidates to get the highest recall i.e. the complete set of items that might be relevant;
In the second level, we use the ranking model to get the highest recall i.e. positive event.
Usually, the positive event can be divided into two types:
Explicit target: rating, purchase event, etc., but they are rare;
Implicit target: some proxy of explicit target like click, start watch, etc., we have more such data in general
There is no unique way to define the target, but in the industry, we use a combination of both with preliminary research on the target.
Finally, in recommendations we should consider special cases that require thorough analysis:
Cold Start problem – user does not have any history on our platform
Items which the user has already interacted with - there is no need to recommend films or books again, but it is ok for groceries, for example;
In the next section, we will define a baseline for recommendation tasks based on the heuristic method and implement it.